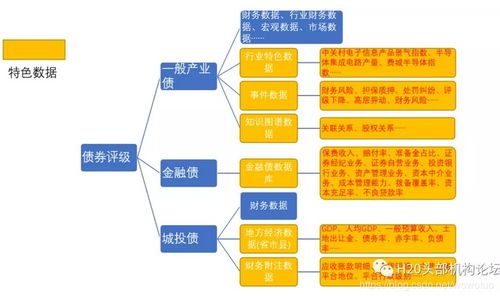
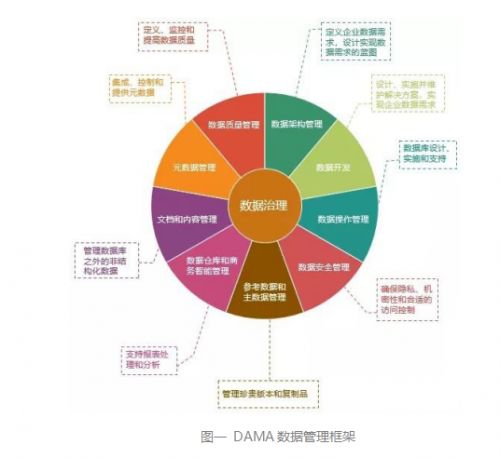
數據治理架構中的數據處理服務 核心組件、挑戰與最佳實踐
在當今數據驅動的商業環境中,一個健全的數據治理架構是企業實現數據資產價值最大化的基石。而數據處理服務,作為該架構中承上啟下的關鍵執行層,其設計與實施的質量直接決定了數據治理的成效。本文旨在對數據治理架構中的數據處理服務進行與分析,探討其核心角色、面臨的挑戰以及未來的發展趨勢。
一、數據處理服務在數據治理架構中的定位與核心組件
數據治理架構通常分為戰略層、組織層、策略層和執行層。數據處理服務主要位于執行層,是具體落實數據質量、安全、生命周期等治理策略的技術實現載體。它并非單一工具,而是一個集成了多種技術和流程的服務集合,主要包括:
- 數據集成與攝取服務:負責從異構的源系統(如業務數據庫、日志文件、物聯網設備、第三方API)中抽取數據,并進行清洗、轉換和加載(ETL/ELT),為后續處理提供高質量、一致的數據源。這是確保數據“可用”的第一步。
- 數據質量管控服務:在數據處理流水線中嵌入質量檢查規則。通過實時或批量的方式,對數據的完整性、準確性、一致性、唯一性和時效性進行監控、評估與修復,是保障數據“可信”的核心。
- 主數據與參考數據管理服務:確保關鍵業務實體(如客戶、產品、供應商)數據在全企業范圍內的統一、準確和權威。該服務維護“黃金記錄”,為所有分析應用提供一致的主數據視圖。
- 元數據管理服務:捕獲、存儲和管理關于數據的技術元數據(如數據結構、血緣關系)和業務元數據(如業務定義、負責人)。它為數據處理過程提供上下文,支持影響分析、血緣追蹤和合規審計。
- 數據安全與隱私服務:在數據處理過程中實施加密、脫敏、訪問控制和數據遮蔽策略,確保敏感數據在存儲、傳輸和使用環節符合法律法規(如GDPR、個保法)與內部安全政策。
- 數據處理編排與調度服務:負責協調復雜的數據處理流水線,管理任務之間的依賴關系、執行順序和資源調度,確保數據處理作業高效、可靠地運行。
二、數據處理服務面臨的主要挑戰
盡管技術不斷進步,但在實踐中,構建和運維高效的數據處理服務仍面臨諸多挑戰:
- 復雜度與規模:數據源激增、數據量爆炸式增長、處理邏輯日益復雜,對服務的可擴展性、性能和穩定性提出了極高要求。
- 實時性需求:從傳統的T+1批處理向實時、準實時流處理演進,要求架構能夠支持低延遲的數據處理與服務。
- 技術棧異構:企業往往存在多種數據處理技術和平臺(如Hadoop生態、云數倉、流處理引擎),整合與管理這些異構環境是一大難題。
- 成本控制:計算、存儲資源的成本,特別是云上成本,需要精細化的管理和優化。
- 組織與流程協同:數據處理服務的高效運轉不僅依賴技術,更需要與數據治理的組織、流程緊密配合。跨部門協作不暢是常見的失敗原因。
三、發展趨勢與最佳實踐
為應對上述挑戰,數據處理服務的發展呈現出以下趨勢,并形成了一些行業最佳實踐:
- 云原生與平臺化:采用容器化、微服務、Serverless等云原生技術構建數據處理平臺,實現彈性伸縮、高可用和敏捷部署。平臺化思維有助于統一技術棧、降低運維復雜度。
- 批流一體化:借助Apache Flink、Spark Structured Streaming等框架,構建統一的批流融合處理架構,用同一套代碼邏輯處理歷史和實時數據,簡化開發運維。
- DataOps的興起:將DevOps理念引入數據領域,強調數據處理流程的自動化、監控、協作與快速迭代。通過CI/CD管道實現數據處理作業的自動化測試與部署,提升交付效率和質量。
- 主動與智能化的數據質量管理:利用機器學習和人工智能技術,實現異常模式的自動檢測、數據質量的預測性維護以及數據清洗規則的智能推薦。
- 隱私增強計算(PEC)的應用:在數據處理環節引入聯邦學習、安全多方計算、差分隱私等技術,實現在不暴露原始數據的前提下進行聯合分析,平衡數據價值挖掘與隱私保護。
- 成本與性能的精細優化:通過數據分層存儲、計算資源自動伸縮、作業性能剖析與優化等手段,實現數據處理成本效益的最大化。
四、
數據處理服務是數據治理從藍圖走向現實的關鍵工程化環節。一個設計優良的數據處理服務體系,能夠高效、可靠、安全地將原始數據轉化為可信、可用、有價值的數據資產,從而賦能數據分析、人工智能應用和業務決策。隨著技術的演進和需求的深化,數據處理服務必將朝著更智能、更融合、更自動化、更安全合規的方向持續發展。企業需要將其置于數據治理戰略的核心位置進行規劃和建設,方能真正釋放數據潛能,贏得競爭優勢。
如若轉載,請注明出處:http://m.zzyoutiao.cn/product/83.html
更新時間:2026-04-06 06:42:01